Overview
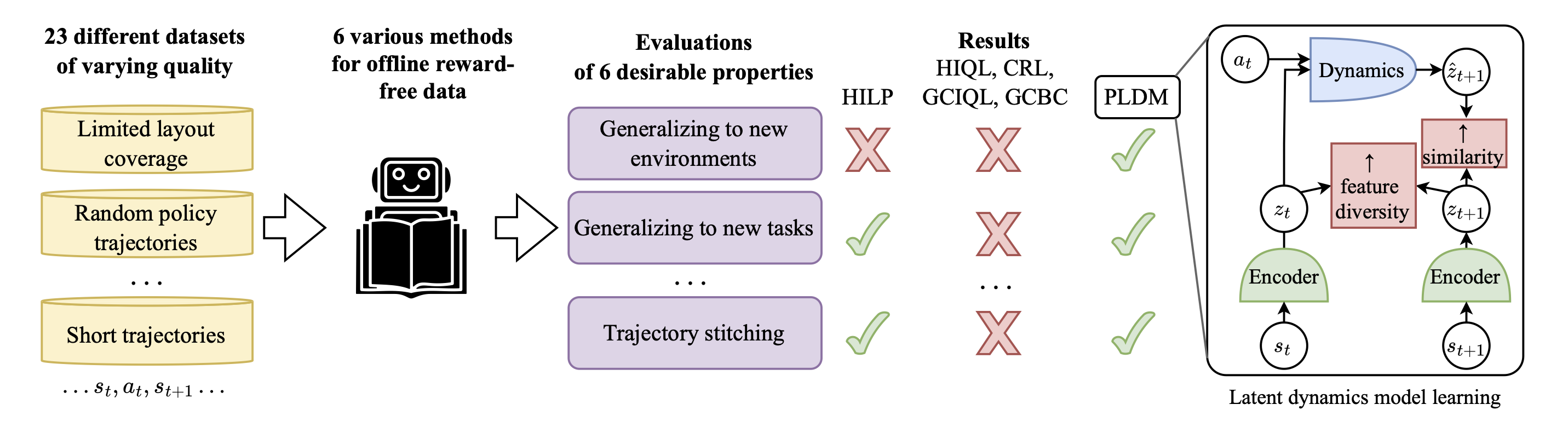
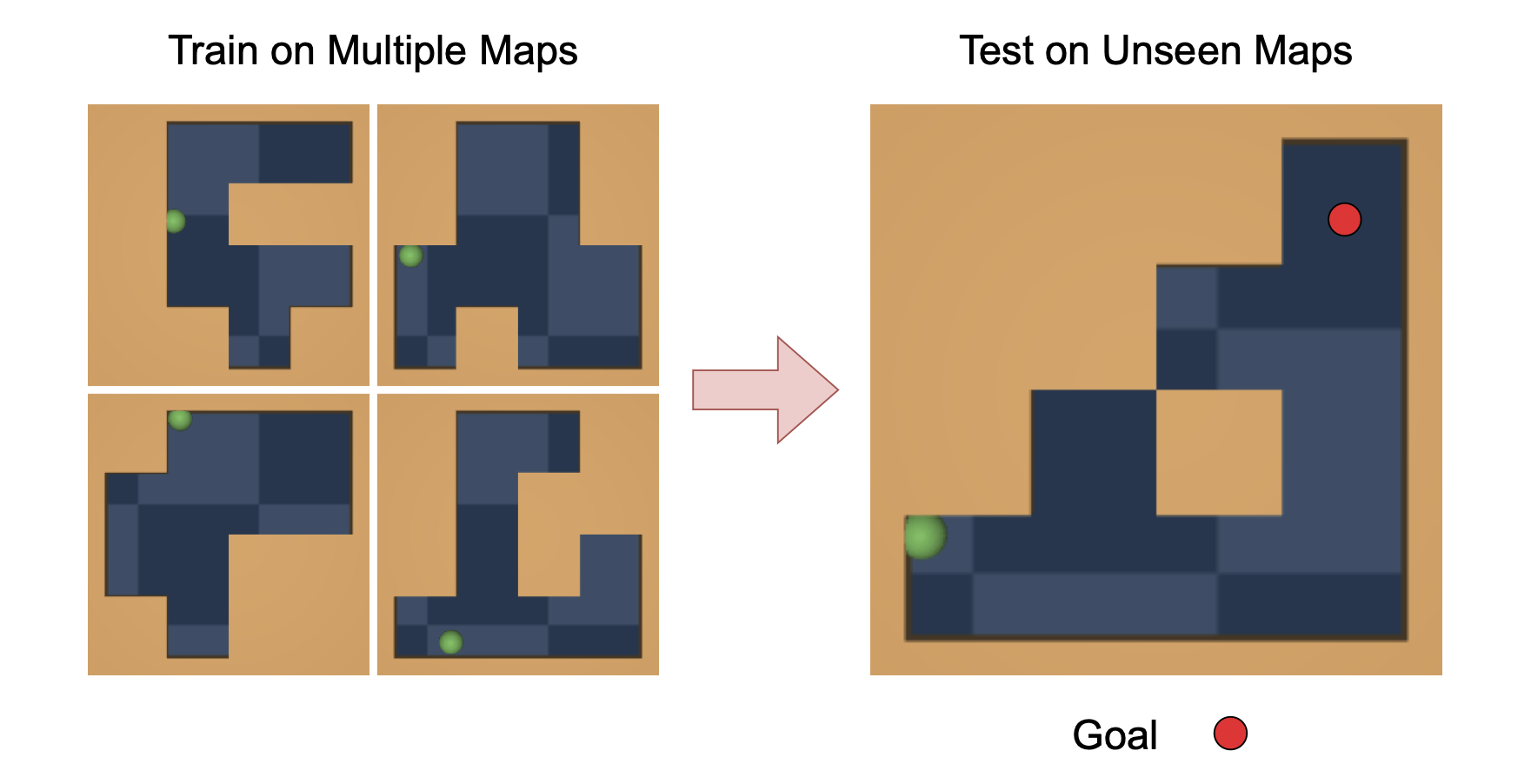
A long-standing goal in AI is to build agents that can solve a variety of tasks across different environments, including previously unseen ones. Two dominant approaches tackle this challenge: (i) reinforcement learning (RL), which learns policies through trial and error, and (ii) optimal control, which plans actions using a learned or known dynamics model. However, their relative strengths and weaknesses remain underexplored in the setting where agents must learn from offline trajectories without reward annotations.
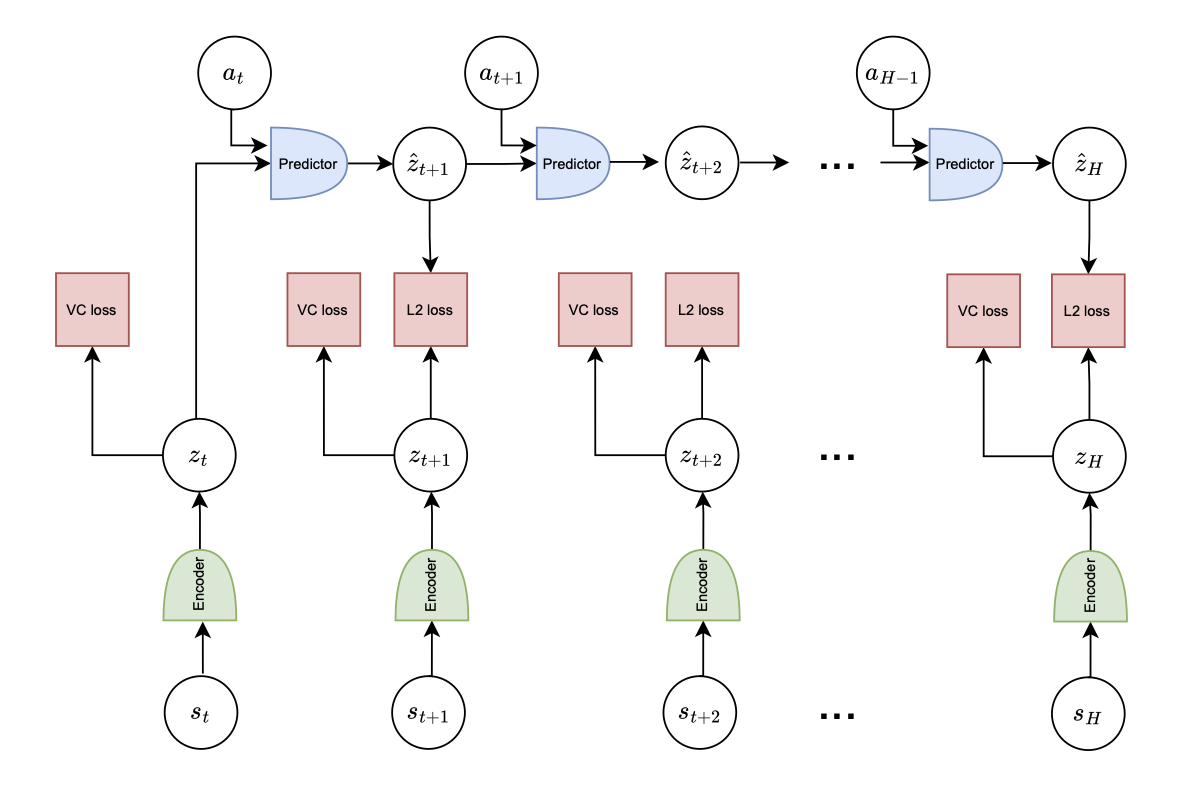
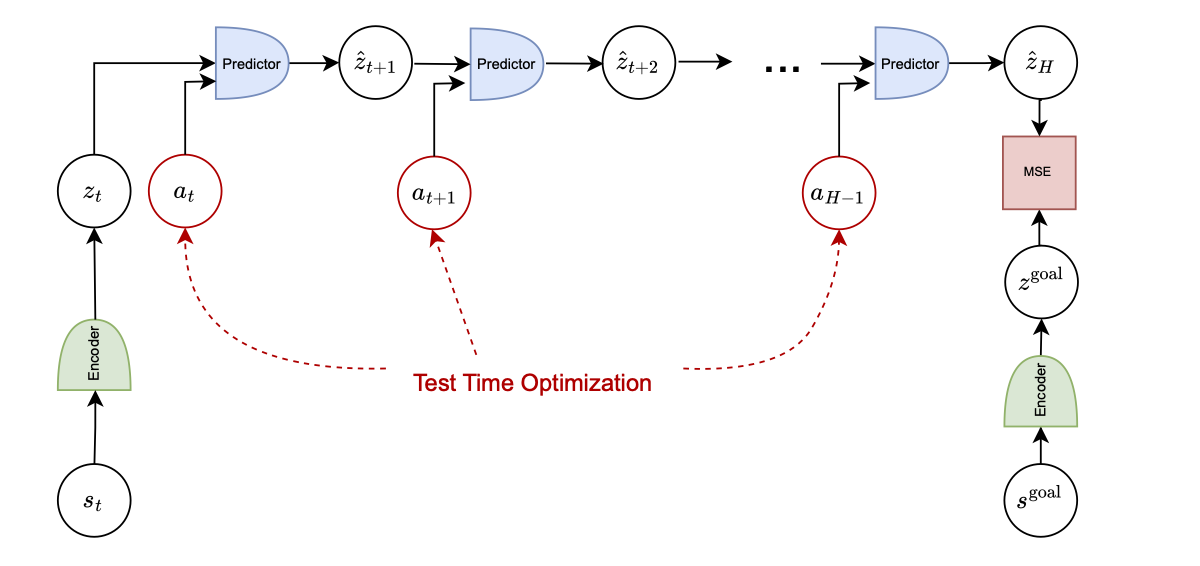
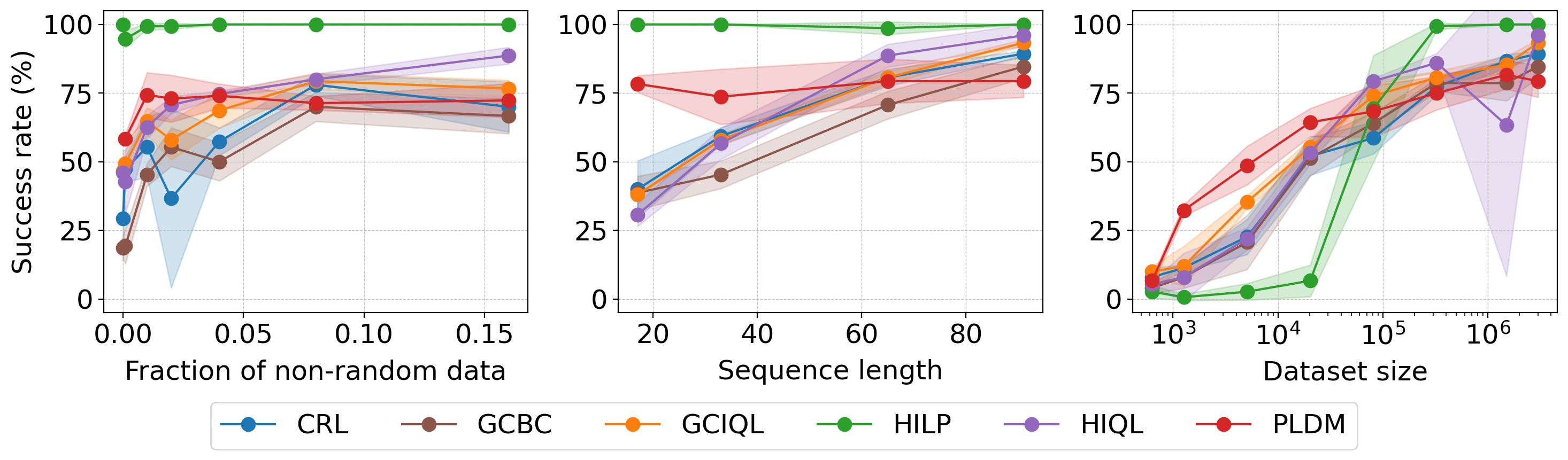
In this work, we systematically analyze the performance of different RL and control-based methods under datasets of varying quality. On the RL side, we consider goal-conditioned and zero-shot approaches. On the control side, we train a latent dynamics model using the Joint Embedding Predictive Architecture (JEPA) and use it for planning. We study how dataset properties—such as data diversity, trajectory quality, and environment variability—affect the performance of these approaches.
Our results show that model-free RL excels when abundant, high-quality data is available, while model-based planning excels in generalization to novel environment leayouts, in trajectory stitching, and data-efficiency. Notably, planning with a latent dynamics model emerges as a promising approach for zero-shot generalization from suboptimal data.
The following GIFs show example trajectories collected in the dataset. These illustrate the variety of movements and behaviors captured in different data settings.
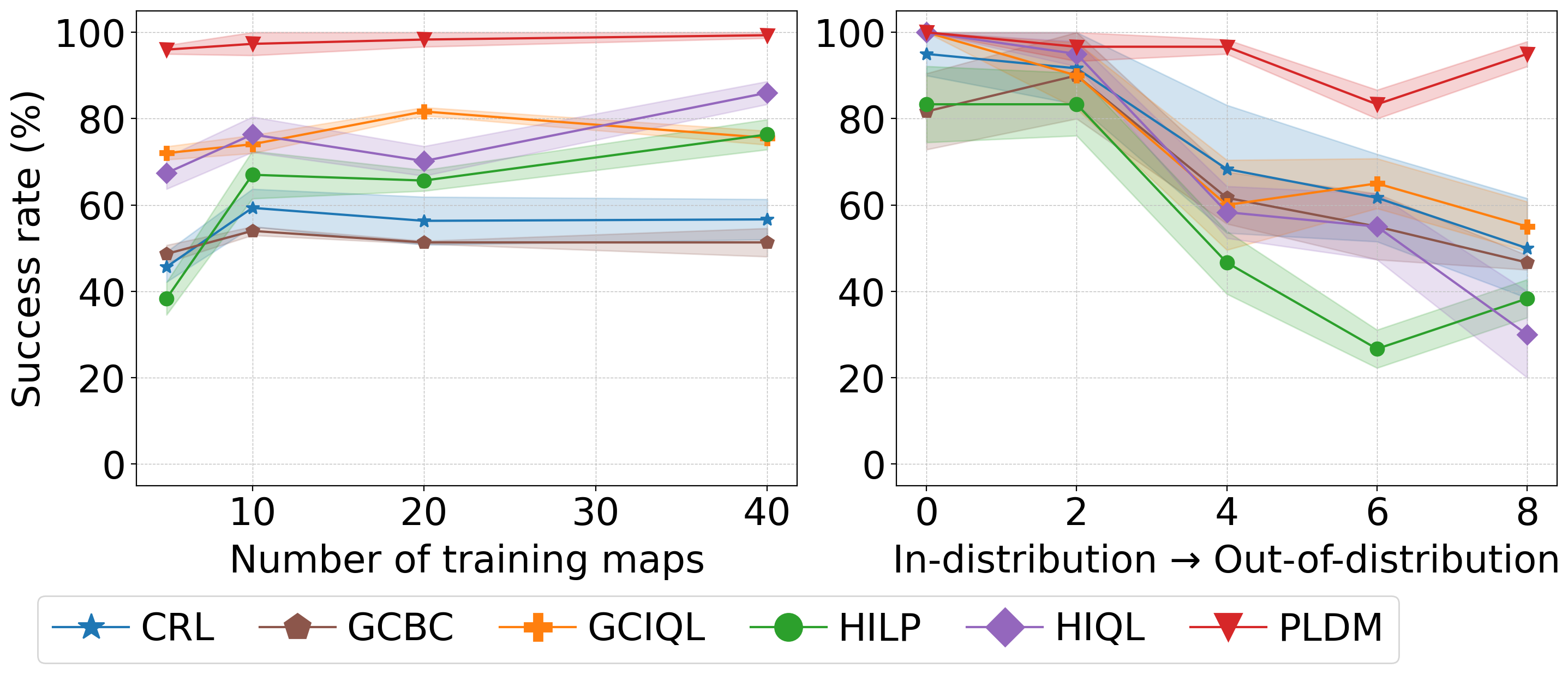
Low distribution shift
CRL

GCBC

GCIQL

HILP

HIQL

PLDM

Medium distribution shift






High distribution shift






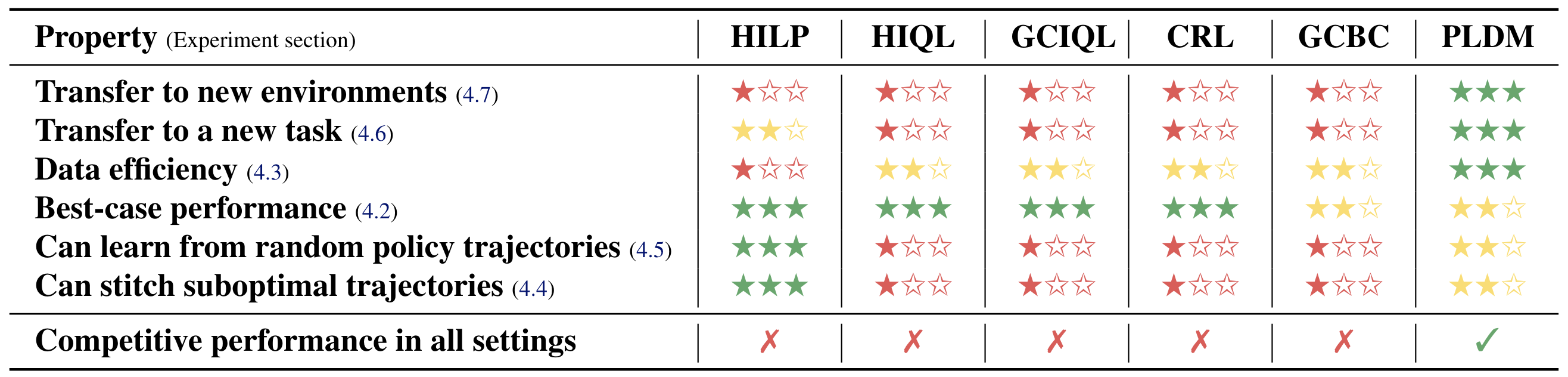
Having thoroughly evaluated six methods for learning from reward-free offline trajectories. The table below summarizes their performance across several key challenges: (i) Transfer to new environments, (ii) Zero-shot transfer to a new task, (iii) Data-efficiency, (iv) Best-case performance when data is abundant and high-quality, (v) Ability to learn from random or suboptimal trajectories, and (vi) Ability to stitch suboptimal trajectories to solve long-horizon tasks.
@article{sobal2025learning,
title={Learning from Reward-Free Offline Data: A Case for Planning with Latent Dynamics Models},
author={Sobal, Vlad and Zhang, Wancong and Cho, Kynghyun and Balestriero, Randall and Rudner, Tim G. J. and LeCun, Yann},
journal={arXiv preprint arXiv:2502.14819},
year={2025},
archivePrefix={arXiv},
}